On April 28, the Ministry of Industry and Information Technology and the National Data Administration jointly released the 2026 “Model-Data Resonance” Action, releasing new policy signals for the systematic construction of industrial AI.
The action targets 20 industries including steel, petrochemicals, non-ferrous metals, automobiles, medical equipment, and power equipment, and clearly proposes to build industry general knowledge datasets, industry specialized knowledge datasets, industry models, and characteristic intelligent agents, promoting the formation of a virtuous cycle of “data-model-scenario application”.
In a May when AI Agents are being released intensively and the industry is flooded with new models every day, this document did not come with much fanfare. But if you read it carefully, you will find that it points to a question that the industry has discussed for a long time but has never had a standard answer:General large models can already write poetry, program, and pass the bar exam, but when you throw them into a real mineral processing production line, or a complex insurance claim settlement process, why should they “understand the industry”?Because problems in industrial scenarios are not open-ended questions.They have objects, relationships, processes, responsibility boundaries, and a large number of rules that cannot be violated.This is what makes “Model-Data Resonance” truly worthy of attention.
The Awkward Moment of the “General Brain”
Not long ago, DeepSeek V4 was released, with 1.6 trillion parameters, million-token context, Agent capabilities reaching the highest open-source level, and inference performance approaching the world’s top closed-source models. The industry was boiling, and securities firms rushed to release reports overnight, defining the second half of 2026 as “an important window for large-scale release of domestic computing power”.
But beneath the excitement, a cold question has been hanging:
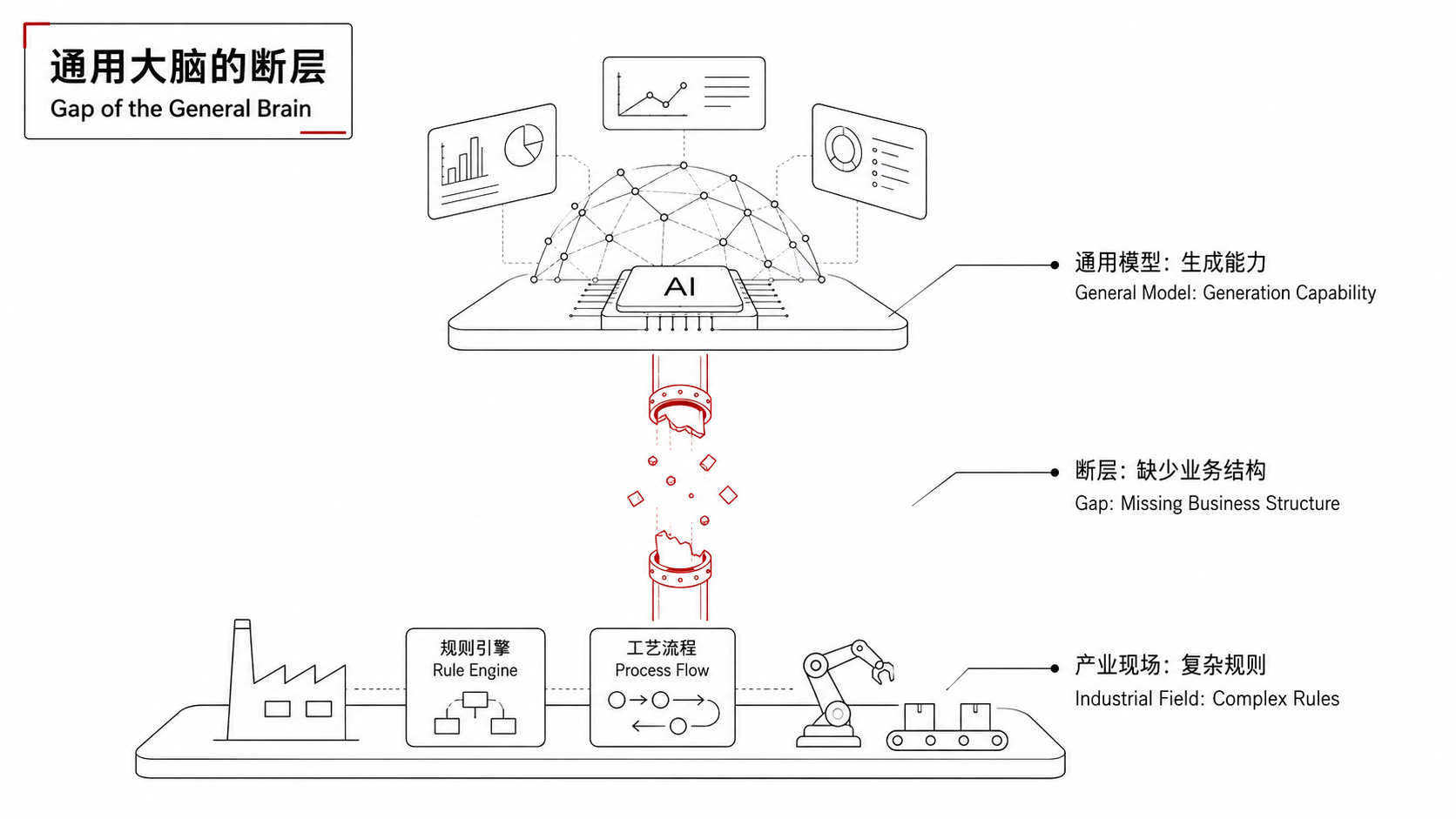
No matter how large the parameters or how long the context, the model still doesn’t know what “abnormal overflow fineness of a ball mill” is, nor does it understand the “waiting period superposition logic in claim triggering rules”.
This is not because the model is not smart enough. On the contrary, it is too smart—so smart that when you ask it to write an industrial analysis, it can weave an answer that seems logically consistent but is actually full of factual errors in fluent language.
One word sums up this awkwardness: “intelligence without knowledge”. It has reasoning ability, but lacks a true understanding of the factual boundaries, business processes, and causal relationships of specific industries.
Someone in the industry made an analogy: It’s like hiring a genius with an IQ of 180 to be your technical director. He has never spent a day in your workshop, never read a single page of operating procedures, but you expect him to give a production line optimization plan in his first week on the job.
Many enterprises have already fallen into this trap.
“Industry Nerves” Are the Scarce Commodity
As the discussion reaches this stage, a cognitive turning point has emerged.For the past two years, the focus of competition in the entire AI industry has been almost entirely on the “brain”—who has more parameters, who has stronger reasoning, who has longer context.But as one general large model after another approaches the bottleneck, “intelligence” itself is becoming a basic capability, and the real scarce commodity has become something else:
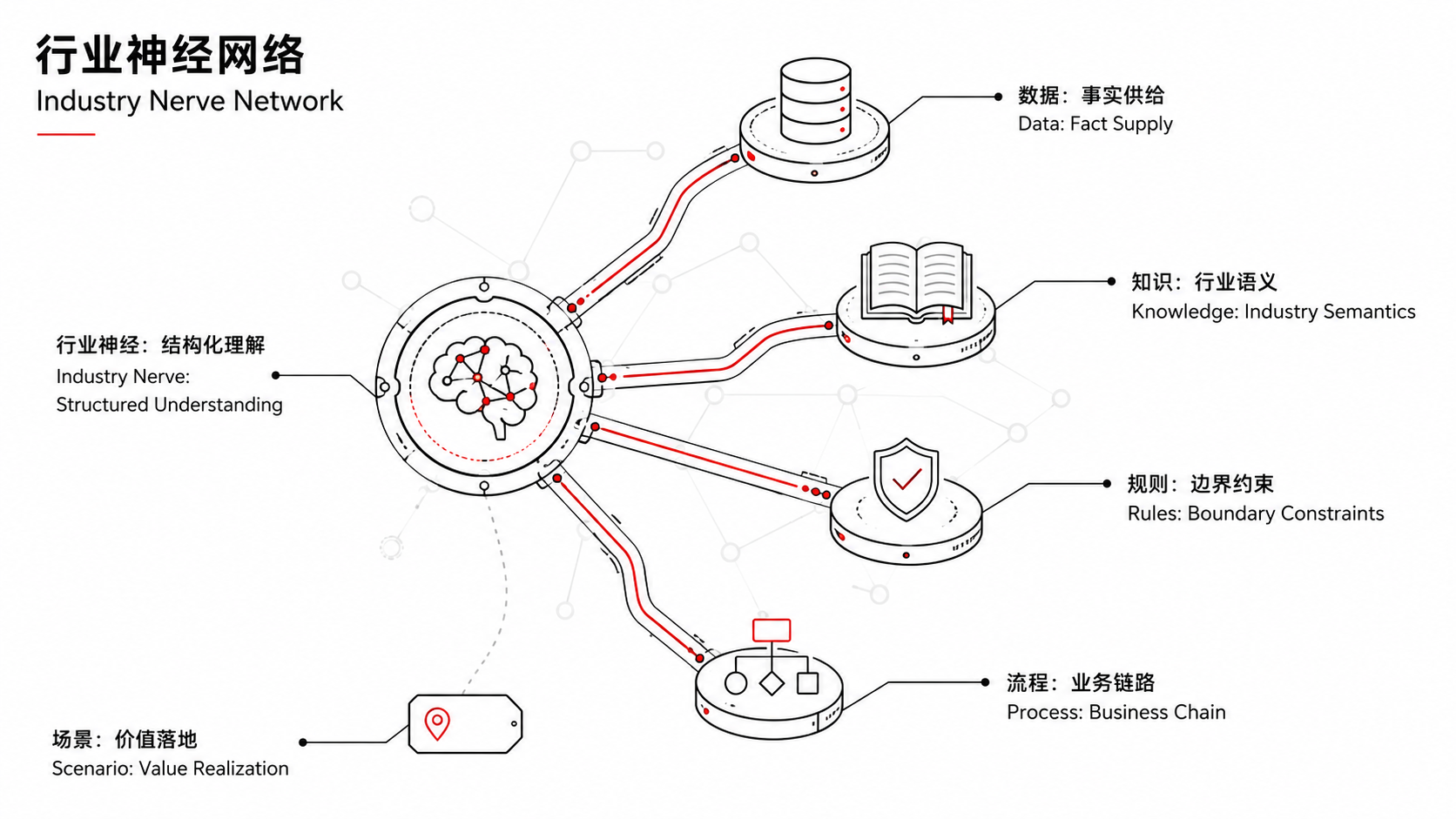
The “industry nerves” that allow models to understand business relationships, factual boundaries, and industrial rules.
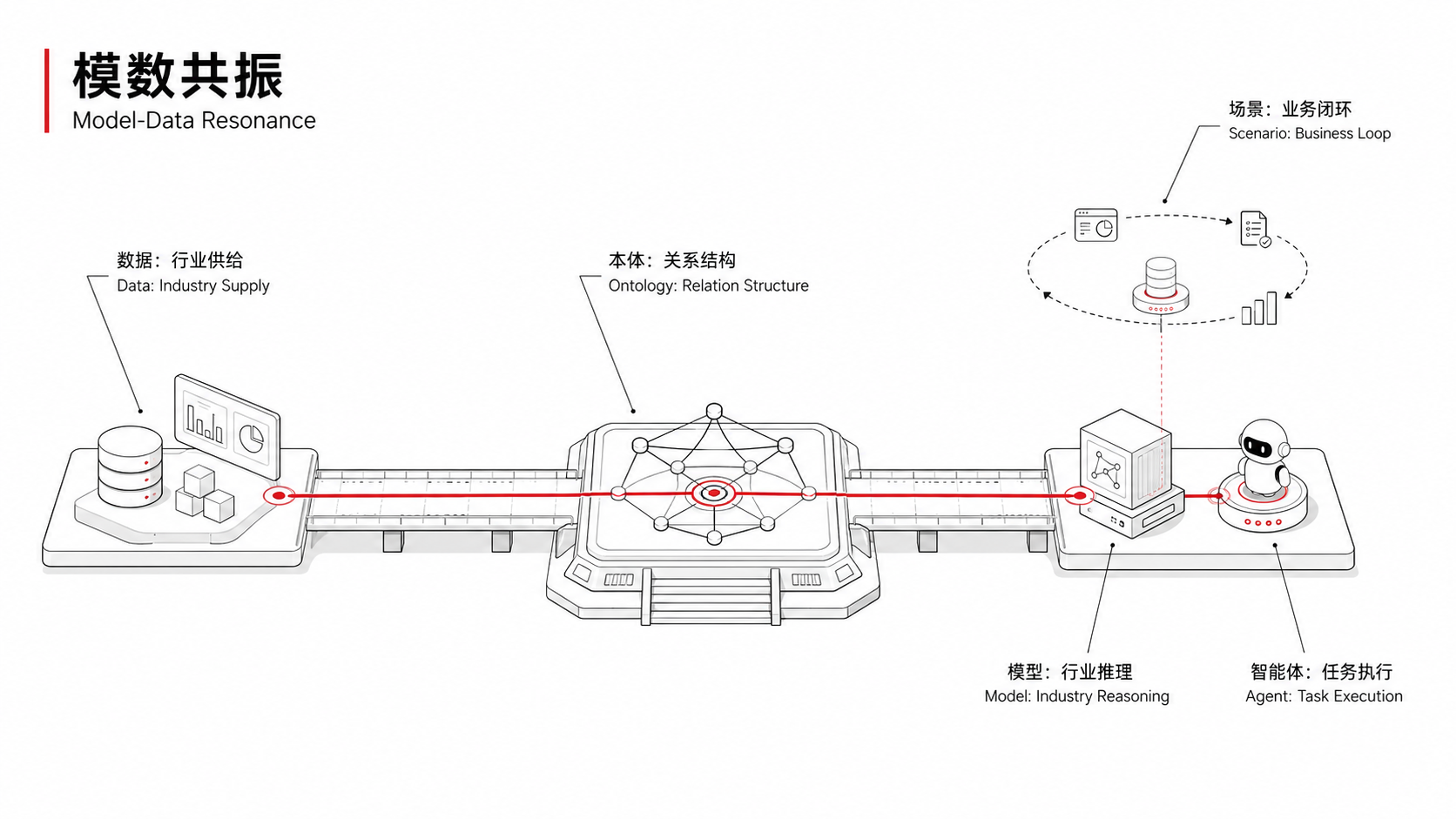
This is also the most noteworthy aspect of the “Model-Data Resonance” Action. It does not propose “training a large model for each industry”, but building a complete system of “industry general knowledge datasets + industry specialized knowledge datasets + industry models + characteristic intelligent agents”.
“Datasets” are placed before “models”.
The policy points to a clear direction:
The bottleneck of industrial AI is not at the model layer, but at the data and knowledge layers.
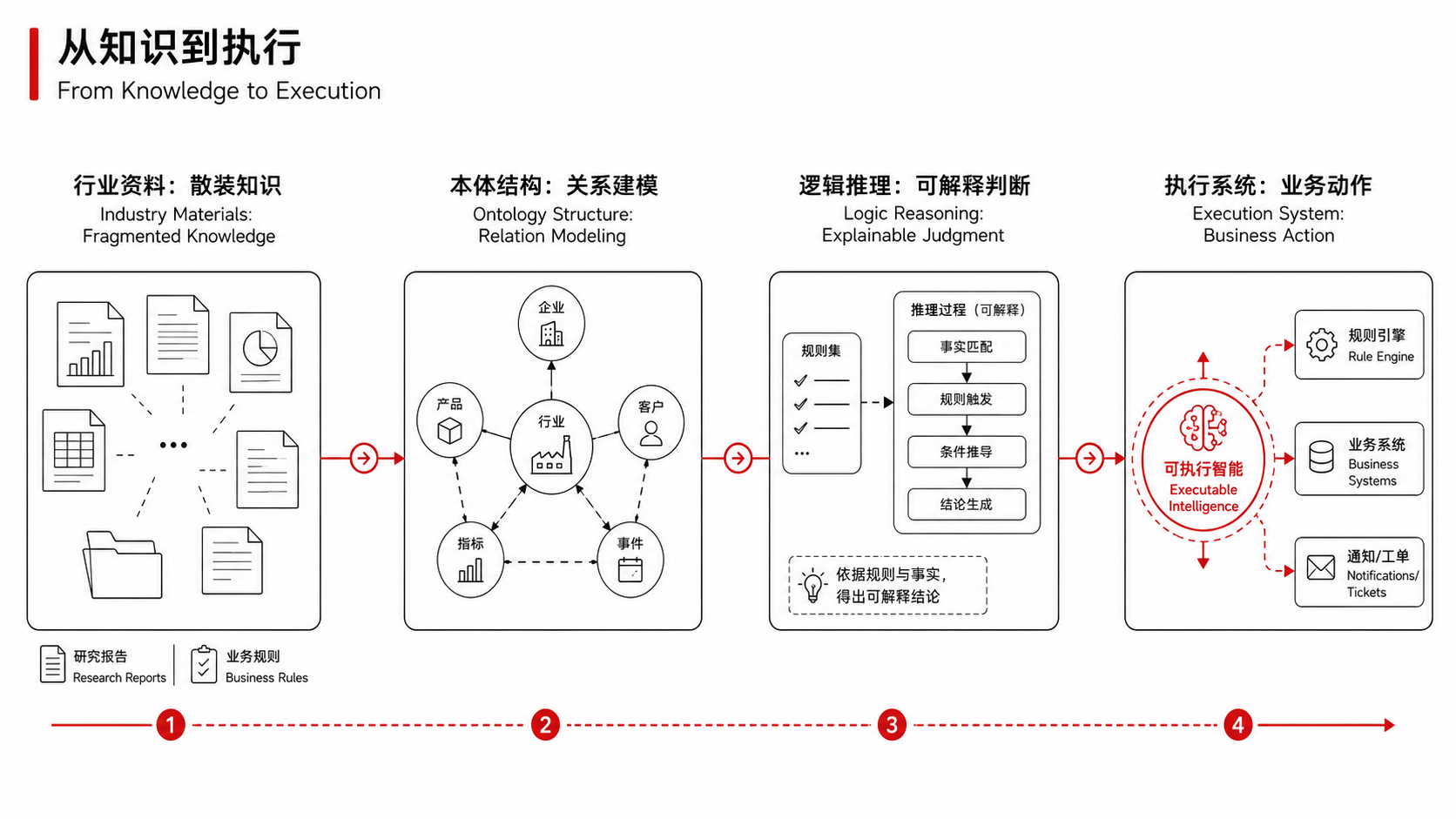
Whether you can organize the knowledge scattered in operating procedures, expert experience, equipment manuals, and historical fault records into a machine-understandable structured system determines whether your AI is truly usable or just an expensive decoration.
And this step is precisely the blind spot that has been covered up for too long by “parameter worship”.
The Center of Gravity of AI Value is Shifting
If you pay attention to industry trends in recent months, you will find that this cognition is accelerating.
Tencent Cloud announced a 5% increase in AI computing power prices, and Zhipu GLM’s Coding Plan increased by 30%-100%. The industry has woken up from the carnival of “free trials” and started to seriously calculate the return on investment for each Token. Zhipu CEO Zhang Peng characterized the price increase as “returning to normal commercial value”.
The subtext is: Enterprises will no longer pay for showmanship; they are only willing to pay for “quantifiable business increments”.
The same story is happening in Silicon Valley.
After Anthropic released nearly 20 major updates intensively, its annualized revenue exceeded $30 billion, but at the same time, the market’s valuation system is undergoing violent shocks. The cycle for an AI company from “being sought after” to “being scrutinized” has shortened from 12-18 months to 3-6 months.
Companies that survive the cycle rely not on the most powerful parameters, but on capabilities that have been verified, polished, and can solve practical problems in real industrial scenarios.
The introduction of the domestic “Model-Data Resonance” Action is equivalent to giving this judgment an official seal of approval.
The signal it sends is clear: The construction standard for industrial AI is shifting from “model capability” to the closed-loop capability of “data-model-scenario”.
Whoever can structure industry knowledge, whoever can make AI truly understand a production line, a set of processes, a group of rules, will get the ticket to the next stage.
Doing the “Difficult but Right” Thing on This Path
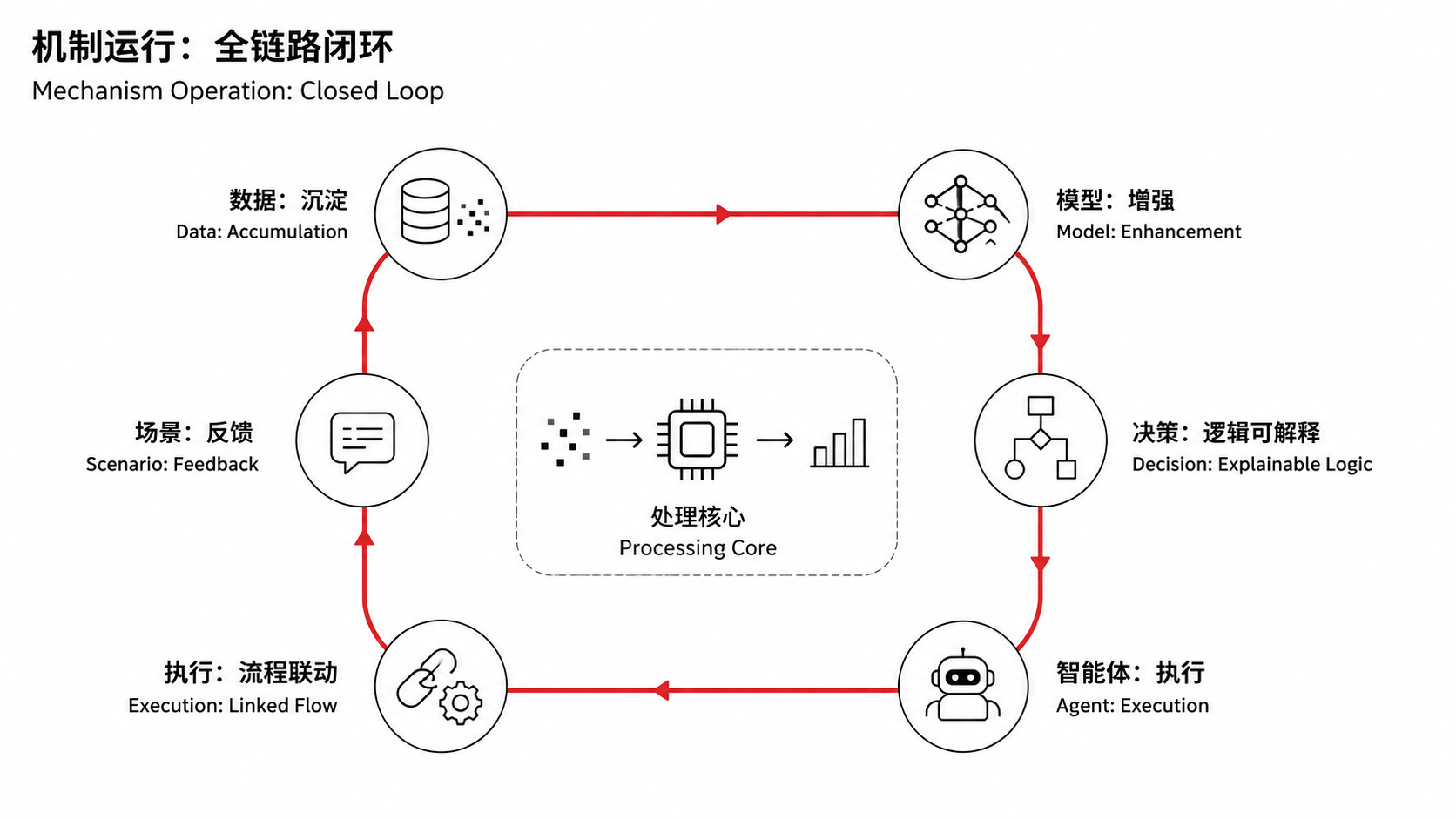
Since its establishment, FundeAI has always placed such a matter at the core of our strategy: building an industrial intelligence system of “dynamic ontology + AI”.
In simple terms, it means structuring industry knowledge, scenario data, and business processes into infrastructure that AI can “read and use well”.
Why must we build “ontology” first?
Because when you need to process real-time data from a mineral processing production line, AI not only has to judge whether the value exceeds the threshold, but also understand what the process flow of this production line is, how to define the normal fluctuation range, and what the root causes behind abnormal signals might be—none of these can be “reasoned out” by general models; they require structured expression of industry knowledge.
Similarly, when you face an insurance claim settlement process with multiple layers of overlapping rules, AI needs to know not just “what the clauses say”, but also the priority relationship between clauses, implementation conventions in historical cases, and special handling logic under the intersection of regions and insurance types.
This is exactly what “Model-Data Resonance” refers to: building industry general knowledge datasets and specialized knowledge datasets to form a virtuous cycle of “data-model-scenario application”.
And it’s what we’ve been doing.
FundeAI’s approach is not to “test business with large models”, but the other way around—first polish the knowledge system completely in real industrial scenarios, and then use AI capabilities to drive it. Dezhen, Deyuan, FundeLight… are all products under this framework.
This path is much slower than directly calling APIs and also tests the depth of understanding of the industry. But it is a reliable path that has been repeatedly verified by industrial practice to solve the problem of “AI being used well in industry”.
The four characters “Model-Data Resonance” may sound abstract to many people when they first hear them.
But translated into plain language, it’s actually very simple: First organize the scattered knowledge in the industry into a form that AI can understand, and then let AI do the work.
This truth is not complicated; the difficulty lies in doing it with patience.
When the entire industry is cheering for “who has larger parameters”, perhaps those who are willing to squat in workshops, on production lines, and in front of business systems, sorting out industry knowledge line by line, will ultimately define how far industrial AI can go.
This may be the real change brought about by “Model-Data Resonance”.
And it’s the future that FundeAI is participating in building.
About FundeAI
FundeAI is committed to becoming a provider of digital economy infrastructure and an enabler of industrial intelligent development.
We take “artificial intelligence + dynamic ontology” as the technical base, and “algorithms, computing power, data, security” as the core, serving multiple industries such as finance and insurance, energy and chemical industry, health management, and smart government affairs. Starting from cutting-edge scenarios, we transform technology into implementable business results, helping with risk control, efficiency improvement, and intelligent decision-making.
We believe that the value of digital intelligence lies in solving complex problems in the real world.