Recently, FundeLight, independently developed by FundeAI, has been officially launched for commercial application. As an AI product built for investment management scenarios, FundeLight is underpinned by an “AI + Ontology” underlying data tool platform. Based on its proprietary framework spanning from Large Language Models (LLMs) to Large Mathematical Logic Models (LMLMs), it enables intelligent assessment of a wide range of enterprise entities. This article elaborates on the underlying logic of FundeLight, starting with the practice of its Version 1.0 release.
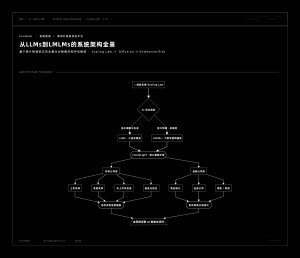
Full Architecture Panorama of FundeLight
From Large Language Models (LLMs) to Large Mathematical Logic Models (LMLMs)
The explosive growth of artificial intelligence (AI) is driven by a deceptively simple principle: the scaling law. Large Language Models (LLMs) have revolutionized our understanding of what machine learning systems can achieve, not through revolutionary algorithmic innovation, but via the systematic scaling of three critical factors:
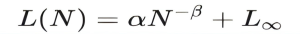
Where L represents the loss function (e.g., cross-entropy loss), N denotes the number of model parameters, α and β are parameters calibrated with domain-specific expertise, and L∞ stands for the irreducible loss floor (i.e., the theoretically achievable minimum loss given unlimited computing resources).
The scaling law, the mathematical relationship describing how model capabilities evolve with scale, gives rise to the emergence phenomenon when machine learning systems reach a sufficient scale.
Large models are far more than large language models. They also encompass image synthesis, video generation, and multimodal content creation, all underpinned by what we call Large Mathematical Logic Models (LMLMs, hereinafter referred to as Large Logic Models). This has made diffusion-form mathematical models the mainstream paradigm in the field.
Here we briefly review the development history of diffusion models. In fact, the concept of modern diffusion models can be traced back to the groundbreaking work on associative memory networks by John Hopfield in 1982. Hopfield Networks introduced the revolutionary idea of framing neural computation as energy minimization, a concept borrowed from statistical physics. In a Hopfield Network, a set of N binary neurons (si) is assigned an energy function:
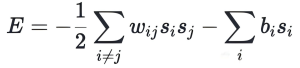
Where wij represents the symmetric connection weights, and bi is the bias term. The network dynamics follow a simple update rule: neurons flip their states to reduce energy, eventually converging to local energy minima corresponding to stored memories. This “energy landscape” analogy laid the foundation for modern generative models.
However, Hopfield Networks have inherent limitations: finite capacity and the tendency of deterministic dynamics to get trapped in local minima. This bottleneck was resolved through a leap forward with the introduction of randomness in Boltzmann Machines, proposed by preeminent AI scholar Professor Hinton (winner of the 2024 Nobel Prize in Physics) and Sejnowski.
In fact, the Boltzmann Machine put forward by Hinton and Sejnowski in 1985 brought about the integration of randomness and statistical mechanics. The shift from deterministic Hopfield Networks to probabilistic Boltzmann Machines represented a paradigm shift linking neural networks to equilibrium statistical mechanics. Boltzmann Machines replaced deterministic threshold updates with stochastic activation based on the Boltzmann distribution via the Gibbs algorithm:
Where:
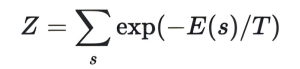
is the partition function, and T is the temperature parameter.
This formalization transformed neural networks into probabilistic models, where states with lower energy have a higher probability of occurrence. This is how diffusion models became the mainstream paradigm: its intellectual lineage extends from Hopfield Networks, to the introduction of randomness and integration with the thermodynamic system in Boltzmann Machines by Hinton and Sejnowski, to the diffusion model architecture we see today. Unified under the same mathematical framework through variational inference, score modeling, and streaming generation based on stochastic algorithm simulation, this lineage has driven the vigorous development of AI large models.
Evolution Topology of Large Logic Models
“Based on the core elements of dynamic ontology (mainly including Objects, Attributes, Relations, Rules, Semantic Consistency Mechanism, and Dynamic Adaptability), combined with our understanding of real-world scenarios, we carry out implementation through creative integration across at least the following three dimensions:
First: Computational Power delivered by neural networks supporting (dynamic) ontology characterization;
Second: Abstract Rules derived from emergent symbolic structures in large model training;
Third: Real-World Foundation endowed by embodied interaction required for real-scenario characterization.
Through this innovative integration, we have built a system and supporting multimodal AI functions that possess both the profound cognitive capability of LLMs and the agile actionable capability of embodied agents. This enables us to bridge the final gap from “thinking” to “action” in the fullest sense via LMLMs, and ultimately build artificial agents that meet human needs.”
We have extended the multimodal framework to capture the joint effects across multiple scaling dimensions. The balanced scaling of the number of parameters (N) and training tokens (D) required for optimal performance, as described above, enables the end-to-end implementation of our proprietary feature extraction method from theory to practice (where E, A and B are coefficients/constants for the corresponding scenarios).
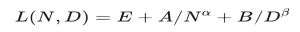
The FundeLight intelligent system launched by FundeAI is a real-world industry implementation of this framework.
In summary, the proprietary innovations of FundeLight include:
- Taking the scaling law driving the rapid development of AI as the fundamental starting point;
- Resolving the bottleneck of Boltzmann Machines based on the Gibbs algorithm for random sampling, realizing the paradigm shift from determinism to stochasticity;
- Establishing the theoretical framework from LLMs to LMLMs;
- Developing an innovative theory-practice integrated method for risk feature extraction tailored to financial scenarios;
- Delivering an overview of the real-world application of our fintech big data AI methodology in the financial industry.
Learn More: Holistic Evaluation Framework of FundeLight
In compliance with regulatory requirements and based on data availability, FundeLight has built a hierarchical, categorized enterprise evaluation framework. It divides domestic enterprises into two major categories: non-financial corporates and financial institutions, which are further subdivided into eight subcategories, enabling a panoramic scan of enterprise risks.
Learn More: Holistic Evaluation Framework of FundeLight
In compliance with regulatory requirements and based on data availability, FundeLight has built a hierarchical, categorized enterprise evaluation framework. It divides domestic enterprises into two major categories: non-financial corporates and financial institutions, which are further subdivided into eight subcategories, enabling a panoramic scan of enterprise risks.
Non-financial Corporate Category
This category covers listed non-financial corporates, bond-issuing non-financial corporates, non-listed non-bond-issuing enterprises, as well as fund and trust companies with unique characteristics of the Funde ecosystem.
For non-financial enterprises, we have introduced multi-source heterogeneous data fusion technology, integrating financial reports, operational dynamics, industry public opinion, supply chain information and more to build an evaluation model based on big data feature extraction. Through automated feature engineering and machine learning algorithms, we mine hidden risk signals beyond traditional financial indicators, such as abnormal related-party transactions, volatility in operational stability, and industry cycle impacts, to form a dynamic, multi-dimensional enterprise credit profile.
Financial Institution Category
This category covers commercial banks, securities companies, life insurance companies, and property and casualty insurance companies.
Taking into account the data standardization and regulatory requirements of the financial industry, we adopt a method combining factor analysis and cluster analysis to extract core risk factors including capital adequacy, asset quality, profitability, and liquidity. We use clustering algorithms to identify institution groups across different risk levels, achieving precise evaluation that enables comparability within the same category and differentiation across different categories. This framework not only supports risk measurement for individual institutions, but also provides a unified benchmark for risk exposure aggregation at the group level.
Dual-Track Evaluation Engine Architecture of FundeLight
The innovations of this framework lie in:
- The inclusion of fund and trust companies into the non-financial corporate category, which fully aligns with the business characteristics of the Funde ecosystem and enables full coverage of the Group’s investment targets.
- The adoption of differentiated technical routes for different types of enterprises, which ensures both refined evaluation and the feasibility of data resource utilization.
At present, this framework has been fully implemented, providing a solid underlying foundation for the subsequent functional expansion of FundeLight.
Looking ahead, FundeLight will evolve into a full-suite AI agent product covering corporate investment KYC, primary market, secondary market, and fixed income market. It will enable penetrating enterprise risk measurement, credit rating, issuer and issue rating in the fixed income market, as well as accurate calculation of yield curves and probability of default (PD). By delivering end-to-end automated risk assessment, FundeLight will provide comprehensive intelligent support for asset management businesses.
About FundeAI
FundeAI is committed to becoming a provider of digital economy infrastructure and an enabler of industrial intelligent development.
With “AI + Dynamic Ontology” as its technical foundation and “algorithms, computing power, data, and security” as its core pillars, FundeAI serves a wide range of industries including finance and insurance, energy and chemical engineering, health management, and smart government affairs. Starting from cutting-edge scenarios, we translate technology into implementable business outcomes to empower risk management, efficiency improvement, and intelligent decision-making.
We believe that the value of digital intelligence lies in solving complex problems in the real world.